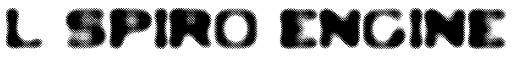

Overview
DXTn is a type of image compression whose decompression is hardware-accelerated, which means you can send the same amount of texture information over the bus to the graphics card for a much smaller bandwidth fee since it does not need to be decompressed before the transfer. This makes DDS files using the DXTn compression scheme (note that DDS files can be non-compressed as well, so it is erroneous to specifically associate the file extension with the compression scheme) the most suitable choice for nearly all game textures these days. Unless you are working on iOS devices.
This article is meant for a more advanced audience, so I will not explain the details of DXTn compression beyond what is relevant to my algorithm. The details can be found in many places online.
http://en.wikipedia.org/wiki/S3_Texture_Compression
http://www.fsdeveloper.com/wiki/index.php?title=DXT_compression_explained
The important point is that DXTn is lossy because each 4×4 texel block is assigned 2 16-bit high and low colors, and the resulting colors inside the block are interpolated at amounts 0.0%, 33.3%, 66.7%, and 100.0% between these colors.
The quality of the compressed image is heavily dependent on selecting the 2 key colors for the block. 2 suggestions as to how to do this are presented here. The clustering method is suggested to be what NVidia uses in their DXTn converter. I will now explain a new method that I have created to produce images of better quality for similar or less processing time.
Comparisons
I took random images from online which fairly accurately model actual game graphics. I will show the original images first, then my conversions, and then NVidia’s. I am keeping the NVidia on its “highest” quality mode, whereas my algorithm is on its medium setting or medium-low setting.
I found a game ad which I can’t show in its entirety, but it is good example material because it has 3 types of imagery: Text, fantasy-style realism, and realism. Unfortunately the realism is on the game logo, so I won’t be showing that here, even though that is where my algorithm really excels.
This is a sampling of text.

Original

L. Spiro Engine

NVidia
Notice how the NVidia characters appear to have more jaggies rather than the softer edges provided by my method. Additionally, in the smaller text there is a much higher degree of distortion and artifacts. Both of the M’s are distorted and a closer view reveals a bit more.

L. Spiro Engine 300%

NVidia 300%
Notice the grey area under the characters in the NVidia sample.
Next is an image with more contrast.

Original

L. Spiro Engine

NVidia
At first glance there does not appear to be much of a difference, however upon closer scrutiny you will notice a lack of contrast in the NVidia sample, particularly in the hair.

Original 300%

L. Spiro Engine 300%

NVidia 300%
The difference is much more noticeable here. My algorithm is able to capture the subtle details at the ends of the strands of hair while maintaining a higher level of contrast along the strands themselves.
The loss of contrast has had a more subtle impact on this particular image. If you look at her eyes, you will notice that in the NVidia sample her attitude has changed slightly. She seems softer and less threatening than in the first 2 samples, although only slightly.
The Algorithm
So how does it work? Most implementations of DXTn compressors work by picking two key colors as a starting point and then adjusting the colors from there via a brute-force search for a better match, adjusting the colors one-by-one. The trick is to find the best possible starting point for the search. As explained in the link above there are at least 2 common ways of doing this. Either from the highest and lowest of the colors in the 4×4 block or by, for example, the average of the highs and average of the lows, etc.
The method I have created uses 2 layers of linear regression in order to create a starting point that is extremely close to the most optimal. The first layer is through each of the unique colors in each channel of the 4×4 block individually. The reds, greens, and blues are sorted from lows to highs and duplicates are removed. Then linear regression is applied to find the most optimal starting and ending points through that cluster of colors.
This alone is not enough. Colors that are similar but not the same will unjustly weigh the sampling points one direction or another, because only one of the 4 sampling points along the line will end up being used for all of the colors. I handle this by converting the colors to their 16-bit counterparts before adding them to the set through which linear regression is later applied.
My second layer of linear regression takes into account that each color can only match up against 1 of the 4 sampling points offered by the 2 key colors. The first layer of linear regression produces the most optimal result only under the assumption that we can sample infinitely along the line between the starting and ending point. With that as a baseline, we can refine the angle of the line segment between the starting and ending points in a way that most reduces the amount of error between the actual colors and the 4 sampling points available to represent those colors. This is an iterative routine, but is still faster than the guess-and-check method commonly used by DXTn compressors.
It works by running over each color in the 4×4 block (again, channels are separate from each other—only the reds are handled, then the blues, then the greens, then alpha) and determining to which of the 4 sampling points it is closest and returning the signed error from that point. The signed errors are accumulated for each of the 4 sampling points separately. The result is the amount by which each of the sampling points is off. The resulting data could look like this:
#0 #1 #2 #3
-0.01 -0.002 0.01 0.03
Here it is clear that the low point is too low and the high point is too high. Linear regression through these error metrics provides the most suitable offsets by which to modify the starting and ending points. This process can be repeated any number of times, each time bringing it closer to the best match.
The last step is a slight bit of guess-and-check, common to other algorithms. We adjust the components of each endpoint one-by-one and check if the resulting color (note that the entire color is checked, not just the colors in the channel we adjusted) would produce better results over the block, and we keep the winner of this check.
Implementation
Firstly it is important to have a good method of deciding how close colors are to each other. When colors within a single channel are compared to determine the amount of error, it is sufficient to simply subtract them (note that colors will be converted to the [0…1] range). But when comparing an entire RGB to another RGB, the channels should be properly weighted. The overall luminance of a color is obtained by adding 30.86% of its red, 60.94% of its green, and 8.2% of its blue (that is, according to ATI; weights of 30%, 59%, and 11% are commonly used as well). Green is the most powerful channel when determining how bright or dark a color is. This is why it gets 6 bits in 16-bit color formats. With this in mind, our routine for determining how much error exists between colors follows.
/**
* A texel in a block of 4×4 for DDS encoding.
*/
typedef union LSI_BLOCK_TEXEL {
struct LSI_COLOR {
LSFLOAT fR, fG, fB, fA;
} s;
LSFLOAT fValues[4];
} * LPLSI_BLOCK_TEXEL, * const LPCLSI_BLOCK_TEXEL;
/**
* Gets the amount of error between 2 colors.
*
* \param _bColor0 Color 1.
* \param _bColor1 Color 2.
* \return Returns the amount of error between 2 colors.
*/
LSFLOAT LSE_CALL CImage::GetError( const LSI_BLOCK_TEXEL &_bColor0, const LSI_BLOCK_TEXEL &_bColor1 ) {
return ::fabs( _bColor0.s.fR - _bColor1.s.fR ) * 0.3086f +
::fabs( _bColor0.s.fG - _bColor1.s.fG ) * 0.6094f +
::fabs( _bColor0.s.fB - _bColor1.s.fB ) * 0.082f;
}
The first step is to create a 4×4 block of texels. This is not presented because it really does not matter how you do this. The algorithm begins once this is done.
Once you have a 4×4 block of texels, the first layer of linear regression is applied as follows.
/**
* Takes an array of 16 texels in floating-point format and determines the two colors best suited to represent
* the given colors via simple interpolation. In other words, it determines the two key colors for a DXT
* block.
*
* \param _bBlock The input block of 4-by-4 texels.
* \param _fMax Upon return, this holds the computed maximum color value.
* \param _fMin Upon return, this holds the computed minimum color value.
* \param _ui32Width Width of the block.
* \param _ui32Height Height of the block.
*/
LSVOID LSE_CALL CImage::GetKeyColors( const LSI_BLOCK _bBlock[4][4], LSI_BLOCK &_bMax, LSI_BLOCK &_bMin, LSUINT32 _ui32Width, LSUINT32 _ui32Height ) {
if ( !_ui32Width && !_ui32Height ) { return; } // Not possible.
static const LSFLOAT fErrorRes[4] = {
1.0f / 31.0f,
1.0f / 63.0f,
1.0f / 31.0f,
1.0f,
};
// For each channel.
CSet<LSFLOAT> sColors;
for ( LSUINT32 I = 4UL; I--; ) {
// We want only unique colors, and we want them sorted.
sColors.ResetNoDealloc();
for ( LSUINT32 Y = _ui32Height; Y--; ) {
for ( LSUINT32 X = _ui32Width; X--; ) {
LSFLOAT fValue = ::floorf( _bBlock[Y][X].fValues[I] / fErrorRes[I] + 0.5f ) * fErrorRes[I];
sColors.Insert( fValue );
}
}
// If there is only one color, it is both the high and the low.
if ( sColors.Length() == 1UL ) {
_bMax.fValues[I] = _bMin.fValues[I] = sColors.GetByIndex( 0UL );
continue;
}
// If there are 2 colors, they are the high and low.
if ( sColors.Length() == 2UL ) {
_bMax.fValues[I] = sColors.GetByIndex( 1UL );
_bMin.fValues[I] = sColors.GetByIndex( 0UL );
continue;
}
// Find the average slope of the colors using linear regression.
LSFLOAT fM = static_cast<LSFLOAT>(sColors.Length());
LSFLOAT fSumX = 0.0f;
LSFLOAT fSumXSq = 0.0f;
LSFLOAT fSumXByY = 0.0f;
LSFLOAT fSumY = 0.0f;
for ( LSUINT32 J = 0UL; J < fM; ++J ) {
LSFLOAT fThis = sColors.GetByIndex( J );
fSumXByY += static_cast<LSFLOAT>(J) * fThis;
fSumX += static_cast<LSFLOAT>(J);
fSumY += fThis;
fSumXSq += static_cast<LSFLOAT>(J) * static_cast<LSFLOAT>(J);
}
LSFLOAT fW1 = (fM * fSumXByY - fSumX * fSumY) / (fM * fSumXSq - fSumX * fSumX);
LSFLOAT fW0 = (1.0f / fM) * fSumY - (fW1 / fM) * fSumX;
// Plug it into the linear equation to get the 2 end points.
LSFLOAT fLow = fW0; // Simplified 0 term for X.
LSFLOAT fHi = (fM - 1.0f) * fW1 + fW0;
_bMin.fValues[I] = fLow;
_bMax.fValues[I] = fHi;
}
// If the min and max are the same, there is no need for refinement.
if ( !CStd::MemCmpF( &_bMin, &_bMax, sizeof( _bMax ) ) ) {
RefineKeyColors( _bBlock, _bMax, _bMin, _ui32Width, _ui32Height, 10000UL );
}
for ( LSUINT32 I = 4UL; I--; ) {
_bMax.fValues[I] = CStd::Clamp( _bMax.fValues[I], 0.0f, 1.0f );
_bMin.fValues[I] = CStd::Clamp( _bMin.fValues[I], 0.0f, 1.0f );
}
}
CSet produces an array of values that are both sorted and non-duplicate. We don’t want to consider duplicates as having more value, because it only takes one of the 4 sampling points between the 2 key colors to satisfy all of them. This is why we convert the colors to their 16-bit counterparts—so that more colors will be merged and eliminated. Also note that the values are never clamped until the end of the routine. If there are only 1 color or 2 colors in the block then a lot of work can be omitted.
Linear regression requires an X and a Y term. For the Y we use the actual color value (per-channel) and for the X we simply use the index of that value within the set. This allows us to find the end points by plugging 0 and fM – 1 into the linear equation.
This in itself gives us good results. If we were to omit the second and third stages altogether, we would get the following results.

L. Spiro Engine
NVidia

L. Spiro Engine
NVidia
The number of artifacts has increased, yet it is still higher quality than the NVidia sample. It is additionally several orders of magnitude faster, having generated this result in under 0.02 seconds (the full image size is 300×268). For professional use, this could act as the “low quality but fast build time” setting, and not only easily replaces the NVidia low-quality setting but could even replace its highest-quality setting (shown here).
Stages 2 and 3 are implemented in the RefineKeyColors() function. First, the second phase of linear regression.
/**
* Refines the given key colors iteratively, with each iteration bringing it closer to the most optimal solution.
*
* \param _bBlock The input block of 4-by-4 texels.
* \param _fMax Upon return, this holds the computed maximum color value.
* \param _fMin Upon return, this holds the computed minimum color value.
* \param _ui32Width Width of the block.
* \param _ui32Height Height of the block.
* \param _ui32Iters Iteration count.
*/
LSVOID LSE_CALL CImage::RefineKeyColors( const LSI_BLOCK_TEXEL _bBlock[4][4], LSI_BLOCK_TEXEL &_bMax, LSI_BLOCK_TEXEL &_bMin, LSUINT32 _ui32Width, LSUINT32 _ui32Height, LSUINT32 _ui32Iters ) {
// We want to determine the amount of error the given key colors will cause over the given block.
// Firstly, the key colors can be matched at any of their 4 interpolation points. We determine amount of error by finding the point
// with the lowest amount of error.
for ( ; _ui32Iters--; ) {
// First create the 4 points that can be matched.
LSI_BLOCK_TEXEL bMatchPoints[4];
Get4Colors( _bMax, _bMin, bMatchPoints );
// For each channel.
for ( LSUINT32 I = 4UL; I--; ) {
// Make the error "buckets".
LSFLOAT fError[4] = { 0.0f };
// For each texel.
for ( LSUINT32 Y = _ui32Height; Y--; ) {
for ( LSUINT32 X = _ui32Width; X--; ) {
// Find out to which point it is closest.
LSFLOAT fMinError = 2.0f;
LSUINT32 ui32Match = 0UL;
for ( LSUINT32 A = 4UL; A--; ) {
LSFLOAT fThisError = bMatchPoints[A].fValues[I] - _bBlock[Y][X].fValues[I];
if ( CMathLib::Abs( fThisError ) < CMathLib::Abs( fMinError ) ) {
fMinError = fThisError;
ui32Match = A;
if ( fThisError == 0.0f ) { break; }
}
}
// Add its error to the appropriate bucket.
fError[ui32Match] -= fMinError;
}
}
// Normalize the error buckets.
for ( LSUINT32 A = 4UL; A--; ) {
fError[A] /= _ui32Width * _ui32Height;
}
// Apply linear regression to the error table.
LSFLOAT fSumX = 0.0f;
LSFLOAT fSumXSq = 0.0f;
LSFLOAT fSumXByY = 0.0f;
LSFLOAT fSumY = 0.0f;
for ( LSUINT32 J = 0UL; J < 4UL; ++J ) {
LSFLOAT fThis = fError[J];
fSumXByY += static_cast<LSFLOAT>(J) * fThis;
fSumX += static_cast<LSFLOAT>(J);
fSumY += fThis;
fSumXSq += static_cast<LSFLOAT>(J) * static_cast<LSFLOAT>(J);
}
LSFLOAT fW1 = (4.0f * fSumXByY - fSumX * fSumY) / (4.0f * fSumXSq - fSumX * fSumX);
LSFLOAT fW0 = (1.0f / 4.0f) * fSumY - (fW1 / 4.0f) * fSumX;
// Plug it into the linear equation to get the 2 end points.
LSFLOAT fLow = fW0; // Simplified 0 term for X.
LSFLOAT fHi = 3.0f * fW1 + fW0;
_bMin.fValues[I] += fLow;
_bMax.fValues[I] += fHi;
// This could cause the low and high to change order.
fLow = _bMin.fValues[I];
_bMin.fValues[I] = CStd::Min( _bMin.fValues[I], _bMax.fValues[I] );
_bMax.fValues[I] = CStd::Max( _bMax.fValues[I], fLow );
}
}
This starts by creating the 4 colors that can be sampled from the 2 key colors. The important thing to note is that the colors it creates are the actual colors that could be sampled. It correctly converts the 2 key colors to the actual 16-bit values they would be, then back into floating-point. This is necessary in order to gain accurate error metrics.
This allows the 4 sampling points to push the 2 end points up and down. The use of linear regression here allows the buckets to all push together in a compromising fashion.
The last part is to guess-and-check using offsets from the endpoints.
// Last step to refining is to adjust each channel by 1-by-1 and test if the result is a closer match.
static const LSINT32 i32Gran[4] = {
3, // Red.
3, // Green.
3, // Blue.
0, // Alpha.
};
LSUINT16 ui16IntForm[2] = {
ConvertBlockTexelTo16Bit( _bMin ),
ConvertBlockTexelTo16Bit( _bMax )
};
LSFLOAT fError = GetError( _bBlock,
Convert16BitToBlockTexel( ui16IntForm[1] ),
Convert16BitToBlockTexel( ui16IntForm[0] ),
_ui32Width, _ui32Height );
if ( fError != 0.0f ) {
LSUINT16 ui16WinnerMin = ui16IntForm[0];
LSUINT16 ui16WinnerMax = ui16IntForm[1];
// Y is applied to the min, X to the max.
// For all reds.
for ( LSINT32 Ry = -i32Gran[0]; Ry <= i32Gran[0] && fError; ++Ry ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMin0 = ui16IntForm[0];
if ( !Offset16BitColorChannel( 0UL, Ry, ui16TempMin0 ) ) { continue; }
for ( LSINT32 Rx = Ry; Rx <= i32Gran[0] && fError; ++Rx ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMax0 = ui16IntForm[1];
if ( !Offset16BitColorChannel( 0UL, Rx, ui16TempMax0 ) ) { continue; }
// For all greens.
for ( LSINT32 By = -i32Gran[1]; By <= i32Gran[1] && fError; ++By ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMin1 = ui16TempMin0;
if ( !Offset16BitColorChannel( 1UL, By, ui16TempMin1 ) ) { continue; }
for ( LSINT32 Bx = By; Bx <= i32Gran[1] && fError; ++Bx ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMax1 = ui16TempMax0;
if ( !Offset16BitColorChannel( 1UL, Bx, ui16TempMax1 ) ) { continue; }
// For all blues.
for ( LSINT32 Gy = -i32Gran[2]; Gy <= i32Gran[2] && fError; ++Gy ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMin2 = ui16TempMin1;
if ( !Offset16BitColorChannel( 2UL, Gy, ui16TempMin2 ) ) { continue; }
for ( LSINT32 Gx = Gy; Gx <= i32Gran[2] && fError; ++Gx ) {
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMax2 = ui16TempMax1;
if ( !Offset16BitColorChannel( 2UL, Gx, ui16TempMax2 ) ) { continue; }
// Get the amount of error in this new configuration.
LSFLOAT fThisError = GetError( _bBlock,
Convert16BitToBlockTexel( ui16TempMax2 ),
Convert16BitToBlockTexel( ui16TempMin2 ),
_ui32Width, _ui32Height );
// If the error has decreased, keep the changes.
if ( fThisError < fError ) {
fError = fThisError;
ui16WinnerMin = ui16TempMin2;
ui16WinnerMax = ui16TempMax2;
}
}
}
}
}
}
}
ui16IntForm[0] = ui16WinnerMin;
ui16IntForm[1] = ui16WinnerMax;
}
Using a helper function I adjust the channels one at a time on the 16-bit end points and then test if the created color has improved the overall match of the color. i32Gran holds the amount by which each channel should be offset and tested. Usually 1 is sufficient, but this can be increased to get better and better results, at the cost of processing time, and as processing time increases exponentially the results only improve marginally, since the previous set of linear regression cycles typically finds the most or almost optimal solution. After adding threading for higher performance, I have found that 3 can be used on all channels without much of a problem.
The last step is presented for completeness, but is necessary regardless of the algorithm used. In all of the above code we kept the channels separate and kept them sorted from low to high. If we were to leave things at that we would get unexpected results when, for example, the green channel in a block is decreasing but the red channel is increasing. Currently, our key colors maintain that all colors start low or high and go up or down. We must check to see if we need to swap the direction of any channel.
// Until now we have worked on each channel separately such that the mins and maxes are both on one side or the other for each
// channel.
// In the cases in an image where one channel goes down as another channel goes up, this will leave us with nothing but poor matches
// when we try to figure out how much of each of the key colors to use for the respective block texel.
// Here we try every combination of flipping each channel to find the one that is best.
static const LSUINT32 ui32Shifts[4] = {
11, // Red.
5, // Green.
0, // Blue.
0, // Alpha.
};
static const LSUINT32 ui32Bits[4] = {
5, // Red.
6, // Green.
5, // Blue.
0, // Alpha.
};
// For each channel.
for ( LSUINT32 I = 3UL; I--; ) {
LSUINT32 ui32Mask = (1UL << ui32Bits[I]) - 1UL;
LSFLOAT fError = GetErrorStrict( _bBlock,
Convert16BitToBlockTexel( ui16IntForm[1] ),
Convert16BitToBlockTexel( ui16IntForm[0] ),
_ui32Width, _ui32Height );
LSUINT32 ui32Min = (ui16IntForm[0] >> ui32Shifts[I]) & ui32Mask;
LSUINT32 ui32Max = (ui16IntForm[1] >> ui32Shifts[I]) & ui32Mask;
// See if the error decreases with the channel swapped.
// Create the new 16-bit value based off these adjustments.
LSUINT16 ui16TempMin = static_cast<LSUINT16>(ui16IntForm[0] & ~(ui32Mask << ui32Shifts[I]));
LSUINT16 ui16TempMax = static_cast<LSUINT16>(ui16IntForm[1] & ~(ui32Mask << ui32Shifts[I]));
ui16TempMin |= ui32Max << ui32Shifts[I];
ui16TempMax |= ui32Min << ui32Shifts[I];
if ( GetErrorStrict( _bBlock,
Convert16BitToBlockTexel( ui16TempMin ),
Convert16BitToBlockTexel( ui16TempMax ),
_ui32Width, _ui32Height ) < fError ) {
// Swapped is better.
ui16IntForm[0] = ui16TempMin;
ui16IntForm[1] = ui16TempMax;
}
}
_bMin = Convert16BitToBlockTexel( CStd::Min( ui16IntForm[0], ui16IntForm[1] ) );
_bMax = Convert16BitToBlockTexel( CStd::Max( ui16IntForm[0], ui16IntForm[1] ) );
}
Finally, the helper function that offsets channels by index is presented for convenience.
/**
* Offsets a component in a 16-bit R5 G6 B5 color by a given amount. If false is returned, the component
* can't be offset by the given amount.
*
* \param _ui32Channel The channel on the color to modify.
* \param _i32Amount The amount by which to modify the color.
* \param _ui16Color The color to modify.
* \return Returns true if the offset was applied.
*/
LSE_INLINE LSBOOL LSE_CALL CImage::Offset16BitColorChannel( LSUINT32 _ui32Channel, LSINT32 _i32Amount, LSUINT16 &_ui16Color ) {
static const LSUINT32 ui32Shifts[4] = {
11, // Red.
5, // Green.
0, // Blue.
0, // Alpha.
};
static const LSUINT32 ui32Bits[4] = {
5, // Red.
6, // Green.
5, // Blue.
0, // Alpha.
};
static const LSUINT32 ui32Masks[4] = {
(1UL << ui32Bits[0]) - 1UL, // Red.
(1UL << ui32Bits[1]) - 1UL, // Green.
(1UL << ui32Bits[2]) - 1UL, // Blue.
(1UL << ui32Bits[3]) - 1UL, // Alpha.
};
// Get the modified min.
LSUINT32 ui32Mask = ui32Masks[_ui32Channel];
LSUINT32 ui32Min = (_ui16Color >> ui32Shifts[_ui32Channel]) & ui32Mask;
if ( static_cast<LSINT32>(ui32Min) + _i32Amount < 0 ||
static_cast<LSINT32>(ui32Min) + _i32Amount > static_cast<LSINT32>(ui32Mask) ) {
// Modifying by this amount would put the min out of its valid range.
return false;
}
ui32Min += _i32Amount;
_ui16Color = static_cast<LSUINT16>(_ui16Color & ~(ui32Mask << ui32Shifts[_ui32Channel]));
_ui16Color |= ui32Min << ui32Shifts[_ui32Channel];
return true;
}
Conclusion
The most difficult challenge in creating quality DXTn-compressed images is in picking a good pair of initial key colors. Most algorithms pick key colors that they expect will have a large margin of error, and rely on a more exhaustive brute-force search for refinement (the 3rd stage of my algorithm). Most of the compression time is dominated by the search, so they offer low, medium, and high quality settings to allow users to make trade-offs.
The algorithm I have presented here starts with an initial guess that is close to optimal, reducing the time needed for searching and increasing the overall image quality at the same time. The result is both faster and higher in quality.
I may release, with source, a command-line tool that could replace the NVidia tool, at least where basic options (generate mipmaps, rescale image, use X filter for scaling and mipmaps, etc.) are concerned, but this algorithm is easy enough to implement for any studio wishing to improve the quality of their in-game art, and it would allow them to customize it and tailor it to their needs.
L. Spiro
Your algorithm looks very interesting – I’m still trying to absorb it. It differs from the one used in crnlib:
http://code.google.com/p/crunch/
crnlib’s DXT1 endpoint optimizer can efficiently handle any number of input pixels (not just 4×4), so it’s a bit different from other approaches (like squish’s) that don’t scale well. crnlib starts with an approximate set of endpoints and refines them using various technique (perturbation, endpoint neighborhood walking, per-component refinement). Max. quality and scalability with up to hundreds of source pixels was my primary concern.
I’ve put a link to this page from crnlib’s main page.
-Rich
Thank you. I would be interested in seeing how yours compares against nVidia’s. You should post some pictures of yours side-by-side with nVidia’s. I think I will make some diagrams to illustrate my process and make it easier to absorb.
L. Spiro
I haven’t studied your algorithm in detail, but I’d like to point out that in your comparisons you are using the old nvidia compression tools, which use a rather poor compression algorithm. The new open source implementation is based on squish and produces much better results. For example, for your first example I obtain:
NVTT RMSE: 8.00
Spiro RMSE: 8.47
and for your second example:
NVTT RMSE: 7.11
Spiro RMSE: 8.66
You can find the source code at:
http://code.google.com/p/nvidia-texture-tools/
Interesting; I downloaded the latest nVidia tools for this testing, but never saw the open-sourced tool. When I first posted my algorithm the RMSE was fairly significant, but I revised many things and fixed some bugs. While I never got the RMSE quite as low as ATI’s Compressonator (though only off by 0.5% or so over the entire image), I felt satisfied with the results because my routine still maintains more contrast than both tools, and is perceptually as accurate.
“Perceptually” accurate is more important than RMSE. For example, dithering makes an image more perceptually accurate, but increases the RMSE.

That being said, I would still like to get my RMSE down more. I halted my research on DXTn compression to port the engine to iOS and OS X, but once that is done I may study a few more ideas I have for improving the DXTn quality.
L. Spiro
I’ve only quickly looked over the code here, but I think I see a problem.
Please note: I’m ASSUMING that you’re expecting a source image in sRGB, if not the following will need adjusting (the source colour space is important to get the correct output).
Firstly the weighting factors you’re using are wrong:
LSFLOAT LSE_CALL CImage::GetError( const LSI_BLOCK_TEXEL &_bColor0, const LSI_BLOCK_TEXEL &_bColor1 ) {
return ::fabs( _bColor0.s.fR – _bColor1.s.fR ) * 0.3086f +
::fabs( _bColor0.s.fG – _bColor1.s.fG ) * 0.6094f +
::fabs( _bColor0.s.fB – _bColor1.s.fB ) * 0.082f;
}
They should be (0.212656, 0.715158, 0.072186), or approximately:
LSFLOAT LSE_CALL CImage::GetError( const LSI_BLOCK_TEXEL &_bColor0, const LSI_BLOCK_TEXEL &_bColor1 ) {
return ::fabs( _bColor0.s.fR – _bColor1.s.fR ) * 0.21f +
::fabs( _bColor0.s.fG – _bColor1.s.fG ) * 0.72f +
::fabs( _bColor0.s.fB – _bColor1.s.fB ) * 0.07f;
}
But more importantly, the input values MUST be linearised first, for example:
::fabs( sRGBToL(_bColor0.s.fR) – sRGBToL(_bColor1.s.fR) ) * 0.21f;
Where sRGBToL converts the sRGB gamma values to linear.
Thank you for your input. Linear mode is necessary for blending colors but for use in MSE computations it is best to stick to the original color format (whatever that may be). I have done a few tests with linear-mode comparisons and my results had the same artifacts as those on the nVidia side, suggesting that they converted to linear mode for their comparisons.
However you are correct that GetError() is flawed. For the correct implementation, check my revised algorithm here: http://lspiroengine.com/?p=312
In that post you will also find my ponderings on the best weights to use, but I tried your weights and not only does the MSE go down by 0.03 (from 5.02 in my final shot to 4.99) it also looks better to me as a human (see the post as to why MSE itself is a poor judge of human perception).
So I will be keeping your suggested weights as the default. Thank you for the contribution.
L. Spiro